这篇文章由两个事件驱动:
- 前段时间,本届人工智能的赛季里最大的人工智能供应商、在社交和 VR 领域都被黒成狗、在 AI 领域却被称为活菩萨的 Meta 发布了 Llama 2。据说不但能和 OpenAI 的 GPT 系列强行五五开,还可以自己随便 fine-tuning。
- 大概一个月前 llama.cpp 做了 CLBlast 支持。
于是我的 AMD 的 Radeon 显卡不用太折腾也能玩了。下面就写一下在 Ubuntu 22.04 Jammy Jellyfish 下跑 llama.cpp + llama2。
下载模型
好心的 TheBloke 提供了转换好的 Llama2 模型供下载:
・TheBloke/Llama-2-70B-GGML
・TheBloke/Llama-2-70B-Chat-GGML
・TheBloke/Llama-2-13B-GGML
・TheBloke/Llama-2-13B-chat-GGML
・TheBloke/Llama-2-7B-GGML
・TheBloke/Llama-2-7B-Chat-GGML
根据你的内存,选择合适的版本下载。比如 70b 的版本大概需要 31GB~70GB 的内存。我下了llama-2-13b-chat.ggmlv3.q4_K_M.bin
其中 q4 表示 4bit 版本。下好的模型是一个 .bin 结尾的文件,存好,放到 ~/Downloads/llama-2-13b-chat.ggmlv3.q4_K_M.bin。
编译 llama.cpp
Ubuntu 下载好相关工具和库:
sudo apt install git make cmake vim
先 clone 一下 Llama.cpp 的代码:
git clone https://github.com/ggerganov/llama.cpp
官网上说直接 make 就好,但是我这里有点问题,所以换成了 cmake:
mkdir build
cd build
cmake ..
cmake --build . --config Release
构建好的程序会放在 llama.cpp/build/bin,其中 main 是命令程序入口,server 是 Web 服务器入口。
把它复制出来换个名字:
cp ./bin/main/main ../llama-cpu
cd ..
测试一下
在 llama.cpp/examples 下面有几个测试脚本,复制一个改成我们自己的:
cp examples/chat-13B.sh examples/chat-llama2-13B.sh
vim examples/chat-llama2-13B.sh
把 examples/chat-llama2-13B.sh 里面的 MODEL 里模型的路径换成自己的路径,例如
MODEL="/home/lyric/Downloads/llama-2-13b-chat.ggmlv3.q4_K_M.bin"
再把里面的 ./main 换成自己的名字 ./llama-cpu
然后运行:
./examples/chat-llama2-13B.sh
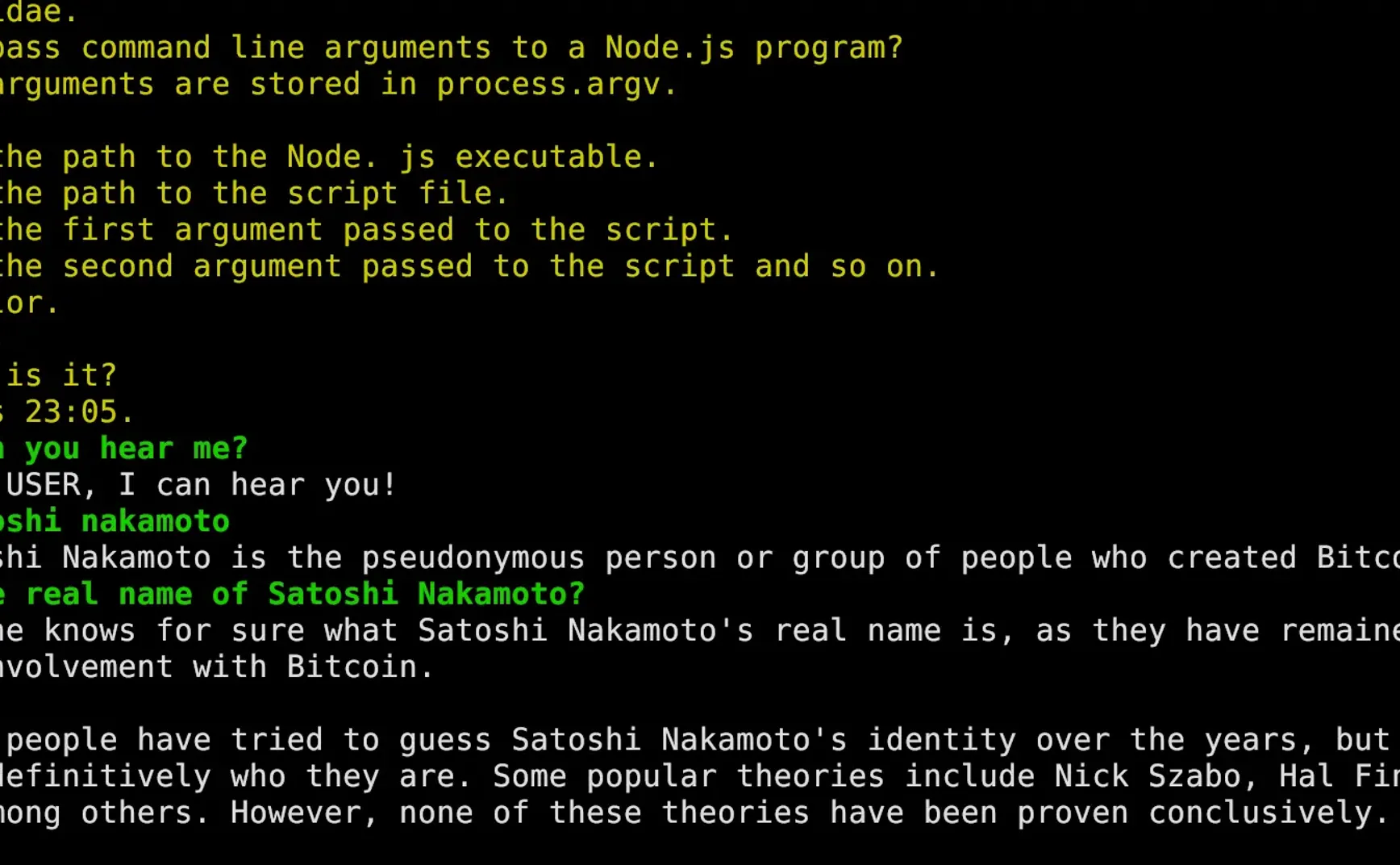
根据你的机器配置的情况,要等一会儿,然后就可以开始聊天了,大概是下面图的效果,其中绿色的字是我输入的,白色的字是 Llama 2 返回的。

启用 GPU 加速
去 AMD 下载驱动: https://repo.radeon.com/amdgpu-install/
注意一下,5.* 版本才是新版,2*.*.* 这种反而是旧版本。旧版本是不能用的。
我安装的 5.5 版本: https://repo.radeon.com/amdgpu-install/5.5/ubuntu/jammy/
装好以后,运行一下:
amdgpu-install --usecase=opencl,rocm
Ubuntu 下载好相关的库:
sudo apt install ocl-icd-dev ocl-icd-opencl-dev \
opencl-headers libclblast-dev
重新去编译一下,加 -DLLAMA_CLBLAST=ON 参数
cd build
cmake .. -DLLAMA_CLBLAST=ON -DCLBlast_dir=/usr/local
cmake --build . --config Release
把它复制出来换个名字:
cp ./bin/main/main ../llama-cl
cd ..
然后改改启动脚本:
vim examples/chat-llama2-13B.sh
把里面的 ./llama-cpu 换成自己的名字 ./llama-cl
然后在倒数第二行加上 --n-gpu-layers 40,例如我的是:
./llama-cl $GEN_OPTIONS \
--model "$MODEL" \
--threads "$N_THREAD" \
--n_predict "$N_PREDICTS" \
--color --interactive \
--file ${PROMPT_FILE} \
--reverse-prompt "${USER_NAME}:" \
--in-prefix ' ' \
--n-gpu-layers 40
"$@"
这里的 --n-gpu-layers 会使用显存来加速 token 生成,我的显卡设置的 40,你可以随便设置一个很大的数字,比如 100000,llama.cpp 会选择显卡最大能用的层数。
然后运行:
./examples/chat-llama2-13B.sh
理论上使用 GPU 加速以后,这次等待时间会短很多,并且应该能在输出里看到类似下面的字样:
ggml_opencl: selecting platform: 'AMD Accelerated Parallel Processing'
...
ama_model_load_internal: using OpenCL for GPU acceleration
llama_model_load_internal: mem required = 710.19 MB (+ 1600.00 MB per state)
llama_model_load_internal: offloading 40 repeating layers to GPU
llama_model_load_internal: offloaded 40/41 layers to GPU
llama_model_load_internal: total VRAM used: 7285 MB
...
就说明有在用 GPU 加速了,在我的电脑上,生成速度大概能到 600+token 每秒,感觉非常快了。
跑个服务
llama.cpp 也提供了 server,可以参考官方文档。
我的话,就直接运行:
./server -m ~/Download/llama-2-13b-chat.ggmlv3.q4_K_M.bin \
-c 2048 -ngl 40 --port 10081
然后打开 http://localhost:10081 就能用 Web UI 了。
这个 Web server 是支持 API 请求的,比如说:
curl --request POST \
--url http://localhost:10081/completion \
--header "Content-Type: application/json" \
--data \
'{"prompt": "Build a website can be done in 10 steps:","n_predict": 128}'
这样就很方便自己拿模型搞事情。
故障排除
OpenCL 的权限问题
有一种情况是只有在 root 权限下才能访问 opencl 相关的函数。比如执行 clinfo 时提示找不到 opencl,但是 sudo clinfo 则正常显示。
那么可以执行一下(把 LOGIN_NAME 换成自己的用户名):
sudo usermod -a -G video LOGIN_NAME
sudo usermod -a -G render LOGIN_NAME
给自己当前用户权限就行。
关于 Llama2 傻傻的问题
OpenAI 的 ChatGPT 是经过了很多 prompt 工程和优化的,但是自己跑起来的 Llama2 没有做过这些事情。所以如果发现 Llama2 傻傻的话,请加大 Prompt 的投喂力度,否则 Llama2 可能很难让您满意。
举个例子,如果你想要 llama2 输出 JSON,需要在 prompt 里提供几个生成 JSON 的例子,类似下面这个意图识别的例子:
You read the following text and recognize user's intent.
Possible intents are:
1. "吃饭"
2. "睡觉"
3. "打豆豆"
9999. "unknown intent"
You must return the intent with the highest confidence.
You must return the result as JSON format.
Here is the template:
{ "id": id, "intent": "USER'S INTENT", "confidence": 0.9 }
**instructions: 我饿了**
{ "id": 1, "intent": "吃饭", "confidence": 0.9 }
**instructions: 困了,想睡觉**
{ "id": 2, "intent": "睡觉", "confidence": 0.9 }
**instructions: 豆豆在哪?我要揍它**
{ "id": 3, "intent": "打豆豆", "confidence": 0.7 }
**instructions: 现在几点**
{ "id": 9999, "intent": "unknown intent", "confidence": 0.9 }
配置到 Web UI 大概是这样:

运行效果如下:

还不错~