在上一篇文章,我说「面向 LLM 的软件系统是新的范式,需要给 AI 少一些约束,更多自由」,然后留了个尾巴:「下次再写具体怎么给自由」。
我想先多问一个问题:为什么我们本能地想给 Agent 加约束?
要回答这个问题,得先理解一件事:在 Agent 的世界里,数据和代码的边界正在消融。
从一个 loop 说起
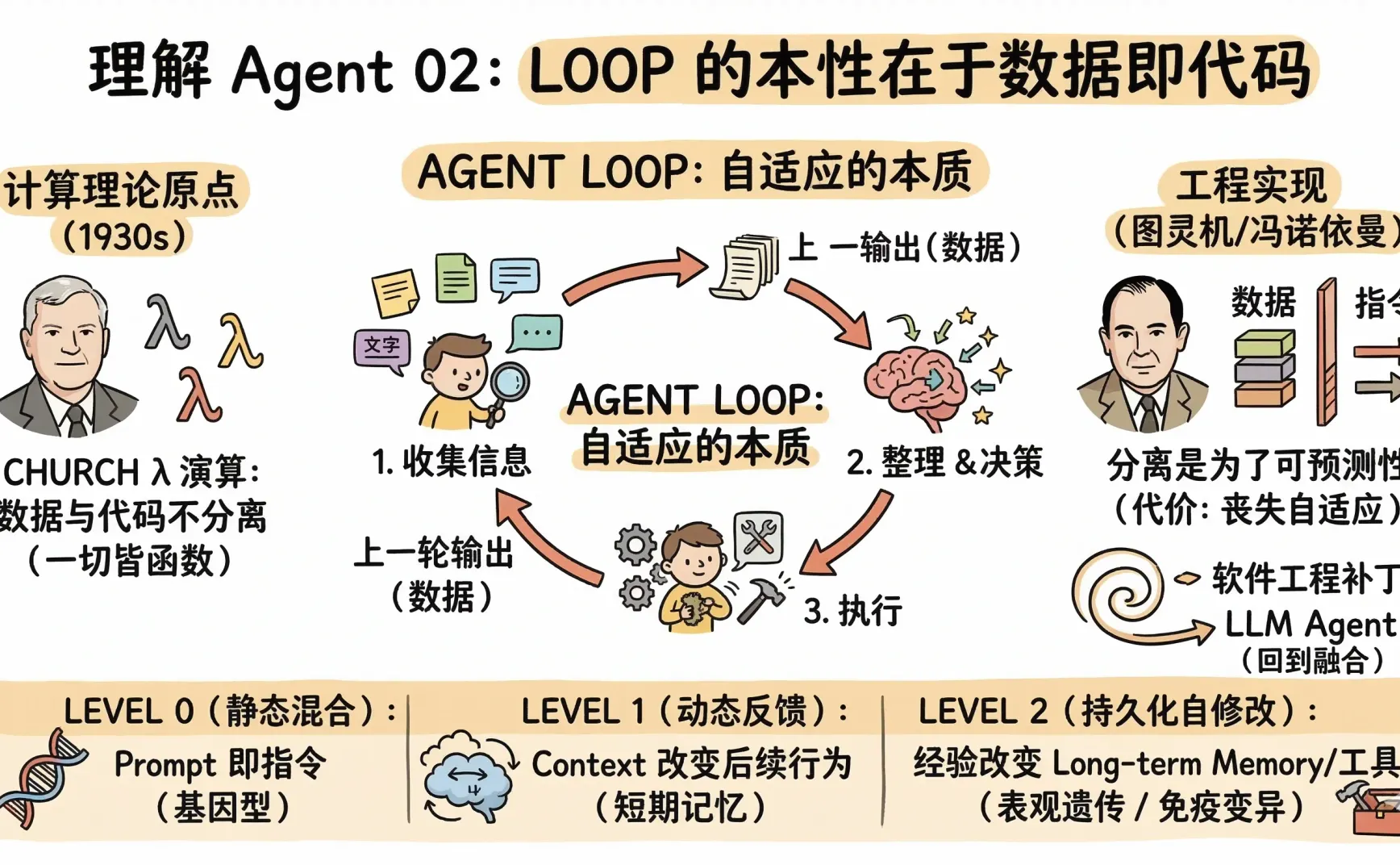
上篇提到,Agent 的核心循环大概长这样:收集信息 → 整理 → 决策 → 执行 → 再收集。
把这个循环用代码来表达,核心就是一个 llm.Chat 调用:你传入 prompt,拿到 response。然后下一轮,你把上一轮的 response 拼进新的 prompt,再传进去。
看起来很简单对吧。但这里藏着一件很不寻常的事:
上一轮的输出(数据),直接变成了下一轮的输入条件(控制流的一部分)。
在传统软件开发里,这是要被打手的。
但这个传统到底从哪里开始?
先回到计算机的起源?
但是如果我们回到计算理论的源头,1930 年代有两条路线几乎同时出现:
Church 的 λ 演算 和 Turing 的图灵机
Church λ 演算里根本没有「数据」和「代码」的区分(可以参考我之前的文章 《Church 计数和 Lambda 演算》)。函数就是值,值就是函数。
Church numeral 本身是一个函数,布尔值是函数,条件分支也是函数。一切都是 λ 表达式,一切都可以被 Apply(当做代码),也可以被传递(当做数据)。数据和代码的融合,不是什么新范式 —— 它是计算理论的原点。
分离反而是后来的事。图灵机把「纸带上的符号」和「状态转移规则」分开了。冯诺依曼架构进一步把分离固化成硬件设计。指令和数据虽然共享存储器,但在逻辑上被区别对待。
我们后续接受了冯诺依曼架构,把数据和指令分开,不是因为这样更正确,而是因为这样更可预测。写一段程序,我们需要知道它在做什么。数据和代码的分离,是为了让人类能理解和控制系统,源于对不可解释的恐惧的本能。
于是,整个现代软件安全模型建立在「数据不应该被当作控制流」这个共识上。
DEP、NX bit、沙箱,全都是在维护这条共识。
代价呢?丧失了自适应能力。
程序不能根据运行结果修改自己的逻辑,自己修改自己?在现代系统里是安全漏洞,不是功能特性。
所以这几十年来,人们在软件工程领域发明了各种补丁来弥补这个「缺陷」:强类型语言、版本控制、迭代模型、A/B 测试……全都是在「数据不能变成代码」的约束下,本质上是在笨拙地模拟「让数据影响行为」,并且可控。
所以更准确的叙事是一个螺旋:
计算的理论起点:λ 演算→ 数据和代码不分离
↓
工程实现:图灵机/冯诺依曼→ 为了可制造性和可预测性,人为引入分离
↓
软件工程 → 在分离的基础上不断打补丁来模拟融合
↓
LLM Agent → 回到融合
loop:系统在用自己的输出重写自己的输入
每次循环迭代,Agent 用自己的输出重写自己的输入条件。这本质上就是自修改程序——只不过修改的不是二进制代码,而是语义空间里的上下文。
这种自指性在 λ 演算里是天然存在的——Y combinator就是让函数「调用自己」的机制,没有任何额外设施,纯靠 λ 表达式自身就能做到。
LLM Agent 的 loop 在某种意义上就是 Y combinator 在语义层的重现。系统通过 loop 不断把自己的输出喂回给自己,产生新的行为。
如果把这件事分层来看,大概有三个级别:
Level 0:静态混合。 system prompt 里的指令本身就是「数据格式的代码」。你写的那段 prompt,既是一段文本(数据),也是在告诉模型该怎么做(代码)。最浅的一层,几乎所有 LLM 应用都在这。
Level 1:动态反馈。 Agent 的输出被拼回 context window,改变后续行为。memory、tool results、chain-of-thought 都是这层的东西。关键特性:短期可逆——context window 有大小限制,这部分信息里,比较旧的部分会被截断。
Level 2:持久化自修改。 Agent 把经验写入长期记忆,修改自己的 prompt 模板,甚至修改自己的工具代码。这层才是真正的 self-evolution。关键特性:不可逆或难以回滚,而且修改的影响可能要很多轮之后才显现。

换到生物学的视角,数据和代码的融合根本就是常态。
DNA 是蓝图,但转录因子本身也是基因编码的蛋白质——代码产生的数据,反过来调控代码的读取。这就是 Level 1。
表观遗传更有意思:不改底层 DNA 序列,但通过化学标记改变基因的表达模式。也就是不改 system prompt,但通过 memory 改变行为。这就是 Level 2。
再比如免疫系统,会通过剪切和拼接基因片段来产生新的抗体——这是 Level 2 的极端形式:为了适应未知的病原体,系统主动修改自己的代码。
所以 Agent loop 的本质可能不是软件在模仿生物,而是:当系统复杂到需要自适应时,数据和控制流的融合是必然结局。
历史上,我们使用冯诺依曼的数据代码分离叙事,可能是工程上的简化需求,不是自然规律。而 λ 演算和生物学从一开始就知道这件事...
新的叙事与叙事切换
生物学里,基因组有两种区域:
- 高度保守的区域:核心代谢通路,几十亿年基本没咋变,动了大概率会死,就没有后代。
- 高度可变的区域:比如免疫球蛋白的可变区。系统鼓励它们突变和重组,动了可能有更强的适应能力。
Agent 的架构应该也是这样:
- 保守区:核心不变量,描述原则,有安全边界,难以修改
- 可变区:自由进化的区域,行为策略、知识记忆、工具使用偏好,鼓励修改
这就回答了「怎么给自由」的前半个问题:不是给,也不是不给的问题,而是在哪里给。
这对软件开发意味着
保守序列在逐步缩小,可变区在逐步扩大。
- 一开始,一切都是保守序列。 瀑布模型、强类型、完整的提前设计。代码写完就不该老变。有效,但只适用于需求可穷举的场景。
- 最近二十年,引入可变区,但严格隔离。 我们有了数据库、依赖注入、A/B 测试。代码和数据能互通,但是必须通过明确的接口交互。可以改配置而不重新编译,配置可以改行为,但配置不能改代码。
- 现在,边界溶解。 Agent 的 prompt 既是数据也是代码。tool calling 的结果直接影响下一步执行什么工具。Agent 可以写代码、执行代码、根据执行结果修改策略。
自由不是约束的反面,自由在正确的约束内才有解释
一开始我们追求一种不变的完美形式:存在一个不变的完美形式,现实世界的需求只是它的投影。传统软件开发追求的是这类思路影响。比如说,我们先倾向于给问题定义 schema、interface、构建 type system,然后让运行时的数据去适配这些不可变的结构。
存在主义翻转了这个关系。存在先于本质——很多时候并不是先有一个固定的定义再去行动,而是通过行动来定义自己。生物和人类本质上就是存在主义的,纯粹的 Agent 的 loop 也是。只有很少的真正的预定义的出厂模式,大部分时候要通过与环境的交互来不断修改自己的定义。
但纯粹的存在主义,在工程上是灾难,这样的系统不可调试也不可信赖。
所以,正如我们需要一些先验的结构,一些很难被经验覆写的东西,比如原则,作为经验有意义累积的起点。Agent 也一样,需要一组很难被自身经验改写的核心约束,让自由进化不至于变成随机漂移。
可以说 LLM 或者 Agent 是一种「语言游戏」。意义不在词语本身,而在使用的规则和上下文中。但这本来也是 LLM 工作的方式——token 没有真正的固有语义,语义由 context 里的关系决定。
所以关系是可以探索的,意义是可以创造的,不再有硬编码的控制流,而是在语义空间内不断坍缩和重组的状态。正如《创造世界是一种什么样的体验 写的那样,我觉得这可能是 Agent 或 LLM 真正让我觉得着迷的部分,
先写到这里
但这个框架只是静态的,Agent 在运行时怎么处理这种融合?
毕竟,画出可变区的边界是一回事,让系统在运行时真正尊重这个边界是另一回事。
对了,上面截图的群聊加入链接是: https://t.me/+tP06DqgNMnlmMTc1