起因是 OpenClaw 火了,我最近又开发了一个 Agent,叫做 Mister Morph。
为什么说「又」呢?因为我之前开发过一个,代号叫 GZK9000,当时域名都买好了:
挖新坑啦 pic.twitter.com/hQxNQJ28HR
— Lyric🌀 (@lyricwai) January 28, 2025
但是烂尾了。
这个 GZK9000。如果按照现在的标准来看,它是一个 Agent,这是它的架构图。
+-------------------------------------------------------------------------------------------+
| gzk9000 Process |
| main -> cmd/root (load config + init DB) -> cmd/server (HTTP + workers) |
+-------------------------------------------------------------------------------------------+
| |
| Online Dialogue Loop (looper + telegram) | Reflective Loop (goalfinder/overthinker)
v v
[Collect Input] Telegram message --> LoopService --> AI reply --> Telegram response
|
v
[Structure Facts] assistant.RecognizeFacts + DetectSentiment
|
v
FactService.CreateFact
| |
v v
PostgreSQL (facts) Qdrant (vectors)
|
v
[Memory Layer] memslices (for later recall)
|
+-------------------------------> [Recall Context] last 24h memslices + facts
|
v
[Find New Goals] extract + dedupe + compare goals
|
v
PostgreSQL (studygoals)
|
v
Guide next questions/thoughts for next input round
|
+----------------------> back to [Collect Input]
它的核心循环是这样设计的:
- 收集信息:
looper从 Telegram 读取消息,产出回复。 - 整理 Fact:
looper调用RecognizeFacts/DetectSentiment结构化输入。 - 事实入库:
fact.CreateFact同步写数据库与 Qdrant 向量索引。 - 寻找新命题:
goalfinder基于近记忆片段与事实提取候选 goals,并与现有 goals 去重后写入studygoals。 - 反复迭代: 新命题会影响后续对话和信息采集,形成「收集信息 -> 整理 fact -> 寻找新命题 -> 再收集」的闭环。
烂尾的原因,现在回过头看,是因为在实现上走了弯路,我后续慢慢说。
什么是 Agent
我的客户曾经问我,为什么测试模型能力的时候,不能用网页版(比如 chatgpt.com 和 grok.com)来测试,而必须用 API。
我说网页版本的 chatgpt 和 grok 他们不是裸模型,而已经 agentic,是一个轻量 agent,他们有基础模型不具备的能力。如果在网页版本输入 list your tools,chatgpt 和 grok 都会列出它们的工具(比如说,搜索、计算器、代码执行等等)。也自带一套「什么时候该用什么工具、失败了怎么重试、怎么把结果写回上下文」的策略。
而 API 更接近「裸模型」:它给你一个推理引擎,但工具怎么接、怎么循环、怎么记录状态,都需要自己实现。所以如果目的是对比模型本身的推理与语言能力,网页端会把变量搅在一起;API 端更可控,更接近你最终在工程里要面对的真实问题。
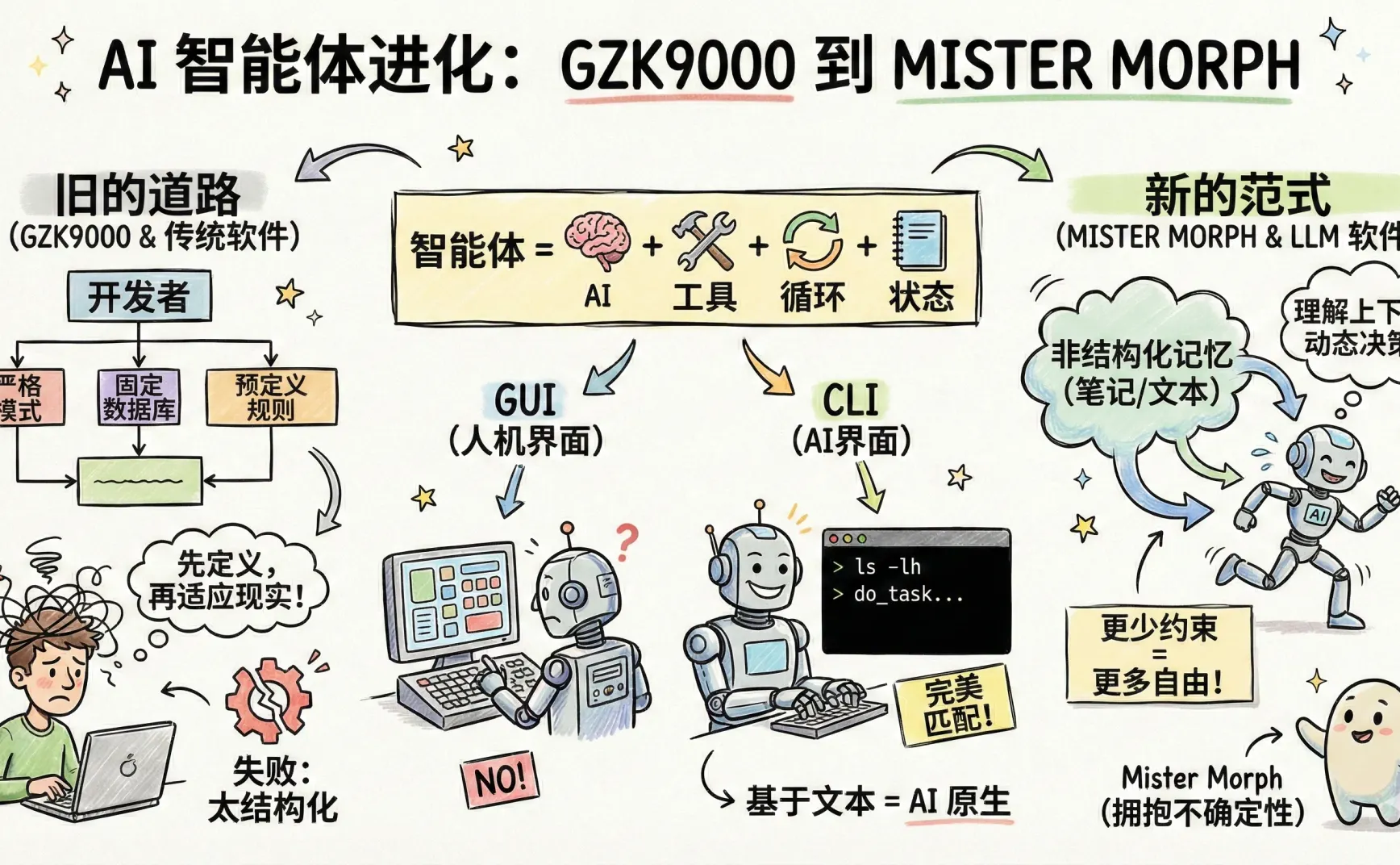
从这个角度看,一个系统想表现出 agentic(aka 能自主推进任务)的特征,通常需要具备几类额外能力:
- 工具:能把「想法」变成「动作」。没有工具,模型只能输出文本,无法真正获取新信息或影响外部世界。
- 循环:能在不完整信息下反复「规划 -> 执行 -> 观察 -> 修正」。一次性问答很难完美,循环让它能不断逼近可用解。
- 状态:能把循环的产物存起来,下次接着用。状态可以是记忆、笔记、任务进度、外部环境变化记录等;没有状态,循环就很难积累进展,只是在原地打转。
所以如果要给 Agent 一个最小定义,我会写成:Agent = 模型 + 工具 + 循环 + 状态
模型负责理解与决策,工具负责行动,循环负责迭代逼近答案,状态负责沉淀,把这次学到的东西带到下一次迭代。这样它才能在噪声和不确定性里,持续推进任务,而不是只做一次性的漂亮回答。
为什么要 Agent
我觉得有两个原因:
第一个原因是 One shot 做不到
因为上下文不完整,所以一次问答很难得到完美结果,Agent 的工作形式天然适合拓展上下文。
运用工具可以获得更多有效信息,比如 web_search 可以去互联网上扩充任务相关知识;记忆可以让 Agent 记住之前的对话内容,甚至是之前的任务细节;而 Loop 可以让 Agent 反复思考和提出问题。
人类也在用类似的方式工作。大脑和感官系统的缓冲区是有限的,没法一次性读入和理解太多东西,所以需要分时切片工作,具体表现:a) 我们会反复向对方提问,来补充所需的信息;b) 我们做笔记;c) 闲暇的时候,大脑会把之前的信息拿回来「反刍」,etc
第二个原因是工具充当了 AI 的手和脚
思考以后得践行对吧。于是调用工具就是 AI 去践行的方式。
人类也是一样。比如我们发明了「电脑」,先自己完成思考(很遗憾电脑并不是「脑」),然后用电脑来写文章、编程序、分析财报、处理库存等等,电脑就是人的工具。
所以自然地,大家会想到把「电脑」这个工具给 AI。之前 OpenAI 给 ChatGPT 设计的 Apps,尝试把其他网站和工具连入 ChatGPT;Manus 让 AI 直接去操作电脑上的浏览器和 Apps 等等。
为什么是 OpenClaw (aka 为什么 Manus / ChatGPT Apps 不行)
现有的 Apps 网站以及他们的交互,是面向人类设计的,天然适合人类的注意力和习惯,天然不适合 AI 的注意力和习惯。
重新发明一套面向 AI 的交互系统又太困难,而且没有生态。
ChatGPT Apps 尝试重建生态,Manus 尝试模拟人类,都很困难。
那怎么办呢?不如看看现在的交互系统中,有哪些适合 AI,同时生态丰富的?答案就是 CLI。于是 OpenClaw 选择了 CLI。
非计算机背景的读者可能不理解 CLI,我来简单说一下:
大部分普通用户接触计算机或者智能手机,都是通过图形化界面元素交互完成。例如点击按钮,输入文本等等。
但是在计算机发展早期,还没有图形化界面的时候,所有操作都是通过命令来完成的。例如,显示当前文件夹下的所有文件使用 ls 命令;显示当前时间需要输入 date 命令等等。
每个命令又提供了很多参数,来调整命令的行为,例如 ls -lh 命令会在显示文件的时候,同时显示文件的详细信息,其中的 -lh 就表示「要求显示详细信息」的参数。
因为没有图像,所有的命令输入都是文本,输出也是文本。
好了,科普结束。
你看,CLI 交互是基于命令的,每一条命令都有非常明确的语义输入,以及非常明确的输出。它的信息流动是二维的,基于文字的,这对同样基于文本的 LLM 来说,不能说是合适吧,只能说是天作之合。
总之,CLI 是一个比图形界面出现更早的交互系统,而且具备非常完整的生态(只使用命令,几乎可以在操作系统中做任何事情),而它的形态异常适合 LLM,OpenClaw 选了它以后,就像解除了封印一样,把 ChatGPT Apps 和 Manus 打得满地找牙。
为什么我的 GZK9000 烂尾
有两个原因:
第一个原因是定位上的问题。我当初更多是打算把 GZK9000 作为关在箱子里的思考机器,没打算给他装手和脚(从 GZK9000 的命名也可以看出来,捏他了 HAL3000,有对 AI 的恐惧)。
第二个原因是工程实现上的问题。我当初是把 GZK9000 当作一个传统软件系统来开发,而不是面向 LLM 的软件系统。
什么叫面向 LLM 的软件系统?这是我自己发明的概念,做了个表来对比:
| 维度 | 传统软件系统 | 面向 LLM 的软件系统 |
|---|---|---|
| 核心假设 | 确定性输入和输出 | 输入输出都是不确定性 |
| 执行方式 | 编排流程 | 动态决策 |
| 数据和代码的边界 | 数据和控制信号区分(数据不应该执行) | 数据与控制信号更紧密耦合(记忆本质上在塑形行为) |
| 记忆机制 | 形式化结构化(比如数据库) | 基于文本语义泛化,非形式化,非结构化(比如文本) |
| 开发方法 | 用逻辑映射现实问题(像解应用题) | 基于 prompt 语义理解 + 逻辑(像个人) |
总之:
传统软件把结构前置,把世界压缩到可计算的形状;面向 LLM 的软件更像人类做笔记:先用弱结构把世界尽量原样收进去,在需要自动化的地方局部结构化。
在具体开发上,agent 的关键逻辑上,大量依赖 llm.Chat 这样的代码,给 llm 传递决策所需信息,然后从 llm 获取决策结果。
GZK9000,作为一个 Agent,依然在沿用传统软件系统的方法开发。
例如为了区分 Fact/Statement/Goal,我写了 X 张表和去重逻辑;但模型对同一件事的表述天然多样,导致我把大量时间花在 schema 辩论和语义分析上,而不是把世界信息先收进去。最终记忆系统既不灵活也难调试。
哎,典型的定义问题先建表、定 schema、再把现实塞进去。
这不对。面向 LLM 的软件系统是新的范式,需要给 AI 少一些约束,更多自由。
今天先写到这里,下次再写具体怎么给自由。