写一个 Agent...
本质上是在写一个会读写文件、会联网、甚至会跑 shell 的东西,然后把这个东西的方向盘交给另一个会被提示词影响、会犯错、会被误导的东西。
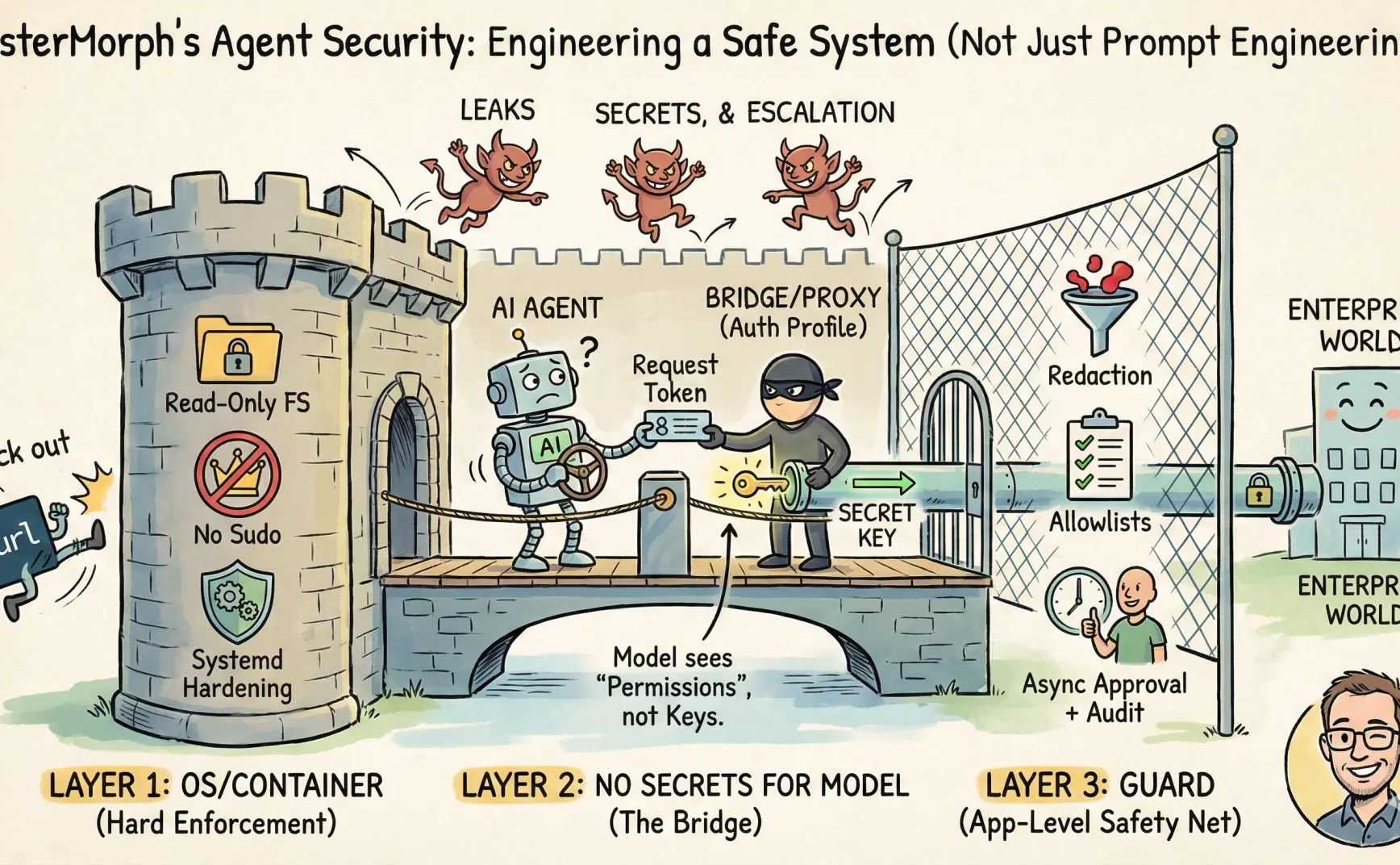
所以我觉得可能把 Agent 当成一种权限系统工程更好,而不是提示词工程。
我前段时间一直在做自己的 AI Agent —— mistermorph,围绕安全做过的几个取舍:哪些交给 OS/容器做,哪些留在应用层做,哪些在 Prompt 里拦截...以及我怎么实现 mistermorph。
本文是经验分享,不是学术论文,不会讲如何完美防御(也不可能)。
详细的实现,欢迎查看 mistermorph 的安全说明书
几个原则
- 不要让 LLM 看到秘密(token、API key、私钥)
- 不要让 LLM 自由拼装 HTTP 请求,它会把秘密带出去
- 控制好 bash 的缰绳
- 能用 OS/容器解决的,别在别的地方重复发明
- 应用层只保留 OS 很难表达的能力:内容 redaction、工作流 approval、目的地 egress allowlist 等等
- 就是最小权限原则
就酱。
威胁模型
Agent 的风险有三类:
- 外泄:把信息发到不该发的地方。
- 泄密:把 key/token 这类敏感信息写进 prompt、日志、tool params、历史消息
- 越权:做了没想让它做的动作(删文件、覆盖文件、跑 shell)
解决这三类风险之前,需要确定系统边界在哪里。
把边界确定了以后,prompt injection 的伤害上限会下降。即使它依然能骗 llm,但会撞墙。
第一层:OS/容器负责能不能做
有些策略更适合交给 OS/容器(或 systemd)做,因为它们有硬的 enforcement:
- 不要给服务进程 sudo,只给普通用户权限。
- 把 rootfs 设为只读,限制可写目录,而不是在 prompt 里设置 sensitive_path 或者 denylist
- 用 systemd 的硬化选项收紧能力面:
ProtectSystem、ProtectHome、NoNewPrivileges、PrivateTmp什么什么的。 - 直接把 curl 等从系统里扬了,只允许用内置的
url_fetch工具
我对 prompt 层的期待很明确:它不是沙箱。它只能把一些“内容/工作流”风险压到最低。如果在企业内网跑 Agent,把把网络 egress 控制也尽量下沉到容器层甚至网络层会更好。
我自己跑 mistermorph 时的实践:用 systemd,普通用户,基本的访问控制(参加这里
第二层:不让模型接触秘密
核心思路就是需要与外部交互时所需的密钥等东西永远不会出现在 prompt 里,而是通过别的东西代持。
具体的解决方案有很多,比如说 MCP 就是一个解决方案,MCP 在其中扮演一个桥的作用;再比如在网络层做拆包做替换也可以。
不过对于 Skills,我给 mister_morph 设计的方案是 auth_profile
实现就是让 agent 自己作为桥,它有密钥;skill 只允许调用 agent 提供的 tools(例如 url_fetch),然后由 agent 在 tools 里注入密钥(例如 url_fetch 注入到 Authorization 头)
即使 mistermorph 也有 guard 去做信息的 redaction,也属于事后擦屁股,避免问题发生更好。
例如,对于 moltbook,它自己原本的 SKILL.md 描述的权限控制不能说没有,只能说完全不存在。
所以在 mistermorph 里,需要进行一些配置,在 moltbook 的 SKILL.md,需要写上一个 auth_profile,名字为 moltbook:
auth_profiles: ["moltbook"]
requirements:
- http_client
- file_io
对应地,在 config.yaml 里需要写上
secrets:
enabled: true
allow_profiles: ["moltbook"]
require_skill_profiles: true
auth_profiles:
moltbook:
credential:
kind: api_key
secret_ref: MOLTBOOK_API_KEY
allow:
url_prefixes:
- "https://www.moltbook.com/api/v1/"
methods: ["GET", "POST", "PATCH", "PUT", "DELETE"]
follow_redirects: false
allow_proxy: false
deny_private_ips: true
bindings:
url_fetch:
inject:
location: header
name: Authorization
format: bearer
于是,moltbook 这个 skill 对外的访问会被限制只能访问约定域名,只能使用约定方法,不需要关系 API Key,因为 agent 会负责注入。哦对,moltbook 的 SKILL.md 我也大幅裁剪了。
当然这类设计的副作用是:配置会更像“权限清单”,而不是“模型的输入”。但这是我想要的副作用。
而且,之后对于 secrets 本身的管理也可以升级。例如从使用环境变量升级到 AWS 的 KMS 去。
第三层:Guard
Guard 这个模块,是用来擦屁股的。擦屁股这件事,要用很多纸。但是在用到最后一张纸之前,你永远都不知道最后一张纸是哪一张。
原因很现实:安全策略的笛卡尔积会把系统复杂度炸掉,比如这样:
- 对每个 tool 都有一套 policy
- 对每个 policy 又按 method/body/headers/path 做细分
- 再加上 prompt 内容检测、上下文审计、IDS 风格规则……
很快得到一个看起来很强,实际很难维护的系统。
所以 MisterMorph 的 Guard 只保留三件事:
1. Outbound allowlist:
典型的就是各类 allow_dirs, allow_url_prefixes。mistermorph 也做了很多。一些是在 prompt 里的安全围栏,一些是在代码级别的限制。
2. Redaction
所有的输入输出,尽可能地用规则去抹掉已知高风险信息。
3. Async approvals + audit
需要人工处理的动作就挂起,返回 pending,让外部系统去处理审批,然后所有风险行为能做审计。
比如说使用 mistermorph 安装 remote skill 时,会先要求用户预览源码,然后使用 llm 做一次审计,然后再确认安装。
总之总之,Guard 更多是一层应用内的安全栅栏,真正的边界还是要交给 OS/容器来画。
最后
过度自信和过度悲观都不好。既不能加几个 prompt 规则就够了,也不要讳疾忌医(只能关机)。我需要在 agent 部署在企业里赚钱呢。
当把钥匙交给 agent 之前,至少要确定 门有几道 / 哪些门是铁门 / 哪些门需要别人点头 / 以及谁在门口记账