
2 月竹白发布下线公告的当天,我发了「🚚 指南:从竹白(zhubai.love)迁移到 Quaily」。
倒不是手有多快,而是 Quaily 很早就支持从竹白导入了~
迁移结果
截止到 2025 年 3 月 31 日,共计迁移了 31 个频道,1715 篇文章,9845 位订阅者。
他们是:
- CyberClip: 一份臻选互联网上有价值内容的赛博剪报,两周一期,涵盖新奇趣闻、热点议题、前沿科技以及其他关于生活、关于未来的事物。
- 熊言熊语: 与你分享肿瘤生物医药领域的研究进展以及我的所思所学所想。
- 为何是他: 以信求知。
- 无限自然: 《无限自然》对优质信息源/AI自动化提效有足够的好奇心,关注AIGC对产品设计的影响。通过逐步建立良好的系统,无限接近自然的状态。
- 素生: 误读人生,化人生活
- 事不过三: 重要的事不过三件:认识自己,好好学习,好好生活。
- 试行错误: 反复探索,不断试错。重在实践和落地。希望能和你一起找到「改变」的突破口!同行的人比目的地更重要。
- 乔尔事务所: 关于地方和空间的观察备忘录
- 海上星光: PM@阿小小海和设计师@尤a娜共营的科技、设计、生活型博客/上海/东京
- 我脑袋里的怪东西: 无聊的通勤 + 奇怪的脑袋。
- Off-Beat: 欢迎看到,这里会存一些个人感兴趣的东西;分享一些个人经历影响下,看到的喜欢的书、音乐、视频、文章;说一些评价、推荐、想法、见闻以及别的该说不该说的乱七八糟的东西吧。
- 日出山谷: 好奇心是智慧的种子!
- 跳歇间: 这是一段时间,也是一个空间。在这里,保持一种轻快的脚步,间歇小跳。
- 有(冇)用: 有(冇)用,源自粤语俗语,意为有(无)用。在当下的生活里,每天信息宛如瀑布般涌现在这小小电子屏幕上,同时信息内涵也悄然变化着,不再单纯且多少夹杂某些目的。但......这些信息是真的有用吗?
- Moonvy月维设计周刊: 每周一更新设计相关的素材和资讯
- 播客相对论: 分享有趣、有意思、值得被更多人听到的播客节目,也希望能在评论中看到你给我推荐一些播客节目。
- 大人的坚持魔法术: 分享一些坚持的魔法,做乌龟赛跑里的乌龟就够了。每周四发出。
- 闲时杂记: 记录生活的美好与不美好✨
- 简悦周报: 简悦周报官方推送渠道,内容涵盖了:新用户指南 / 简悦阅读模式使用技巧 / 通用性问题的处理和解决方案 / 与其它生产力工具的联动 / 简悦用户提供的基于简悦的工作流等。
- 显济的闲言碎语: 下午2:00-5:00在喝咖啡|海外智能硬件产品设计师|做了自己的网站:Jefferyho.com
- 喧哗上等Radio: 播客《喧哗上等》的邮件推送
- 中文播客行业动态: 中文播客领域的动态和最新消息
- 花生碎: 记录是种自我建档。
- 学到老 Shadow law: 一个爱饮咖啡、常听播客、养了只猫的人。读了什么、想到什么,可能都会记录下来,随机从里面抽取片段分享。
- 自说自话: 没有记录就没有发生,而记录本身已经是一种反抗。
- 一颗小树: 分享我的日常,包括但不限于互联网、技术、开源、投资理财,欢迎你来。
- 吾栖之地 | Soul Place: Chuwen的不定期回顾,用文字创作Cyber空间的个人纪录片。
- 驯鹿漫游: 记录我近期收集的有趣信息及一些联想。不定期更新。
- 家书: 以书信形式给青少年看的生命哲思。
- 未闻Code·会员精选: 未闻 Code 精选内容/会员专属内容/我每周的思考总结/我每周学到的新东西。
- 曲率飞船: 这里有诚实真挚的人间体悟,有趣独特的阅读新知。
内容导入
用爬虫抓内容
竹白的网站是一个 Web App,所以常规的爬虫抓不到内容。
所以用了 headless chrome 来抓取内容。
例如,如果要获得文章的标题,发布日期等内容,就在 headless chrome 里运行这一段:
function get() {
const h1 = document.querySelector('h1');
const meta = h1.nextElementSibling;
const content = meta.nextElementSibling;
const metaSpans = meta.querySelectorAll('span');
let dateString = '';
let premium = '0';
if (metaSpans.length >= 2) {
dateString = metaSpans[1].innerText;
}
if (meta.innerText.indexOf('付费内容') !== -1) {
premium = '1';
}
const cover = content.querySelector('figure');
let img = null;
if (cover) {
img = cover.querySelector('img');
}
return {
title: h1.innerText,
date: dateString,
content: content.innerHTML,
cover: img ? img.src: '',
premium: premium,
}
}
而要获得文章列表,则运行这一段:
function getArticles() {
const links = document.querySelectorAll('.PublicationPage_item__38S6L');
let freeLinks = [];
let paidInfo = [];
for (let i = 0; i < links.length; i ++) {
const slug=links[i].href.substring(8, links[i].href.indexOf('.zhubai.love'))
freeLinks.push(`./quail-prod -c ../../config.prod.yaml import -t zhubai -l ${slug} --url='${links[i].href}'`);
const timeEl = links[i].querySelector('.PublicationPage_time__1xXKG')
let time = timeEl.innerText.trim()
// check the first character is digit or not
if (!/^\d+$/.test(time[0])) {
time = time.substring(1).trim()
}
const paidTagEl = links[i].querySelector('.PublicationPage_paidTag__vwcz8')
const titleEl = links[i].querySelector('.PublicationPage_title__1pSF4')
if (paidTagEl && titleEl) {
paidInfo.push({
slug,
title: titleEl.innerText.trim(),
time
})
}
}
let paidSql = [];
for (let i = 0; i < paidInfo.length; i ++) {
paidSql.push(`update posts set first_published_at = '${paidInfo[i].time}' where title = '${paidInfo[i].title}' and slug='${paidInfo[i].slug}';`)
}
return {
freeLinks,
paidSql
}
}
这里对收费文章区分对待,是因为爬虫抓不到收费文章的内容,但是可以抓到收费文章的时间。
把时间记录一下是有用的,看到后面就知道了。
于是,对于免费文章,无论是否有竹白提供的导出数据,只要得到了作者授权,就可以无缝迁移到 Quaily 了。
收费文章内容的导入
三月开始,竹白提供了数据导出,可以导出订阅数据和文章数据。
文章数据里也包括付费的文章,但是实际使用这些数据的时候有两个问题:
- 竹白的导出文章数据里没有文章的发布时间
- 导出数据里的所有链接都是坏链
于是上一个脚本中,抓取付费文章的发布时间就有用了:
使用竹白导出数据完成收费文章的导入以后,再更新一下付费文章的发布时间,那么文章排序才是正确的。
最终完整的文章导入流程变成:
- 免费文章:直接爬虫抓。
- 收费文章:先用备份数据恢复,然后用爬虫抓发布时间,然后更新。
坏链我搞不定,需要作者自己修复了。
订阅者导入
相比内容导入,订阅者导入要简单得多。
竹白导出的订阅信息是一个 csv 文件,大概是这样的格式:
| 用户名 | 邮件地址 | 订阅时间 | 付费时间 | 到期时间 | 累计付费 | 是否为付费用户 |
|---|---|---|---|---|---|---|
| 某某 | [email protected] | 2022-02-09 | - | - | 0.00 | 否 |
我有一个专门的脚本来转换各类订阅信息到 Quaily 的 JSON 订阅格式,其中也包括竹白导出的 csv。
但大量导入很容易命中 ESP 的风控,所以这个脚本会把订阅信息拆分成很多份,每一份都是一个单独的 json 文件。
然后这些 json 文件会被提交给 Quaily 的任务调度程序,这个程序会自己去安排导入任务。
调度程序部署好任务以后,会返回预计完成时间,我会把这个时间通过邮件回复给让我帮迁移的作者。
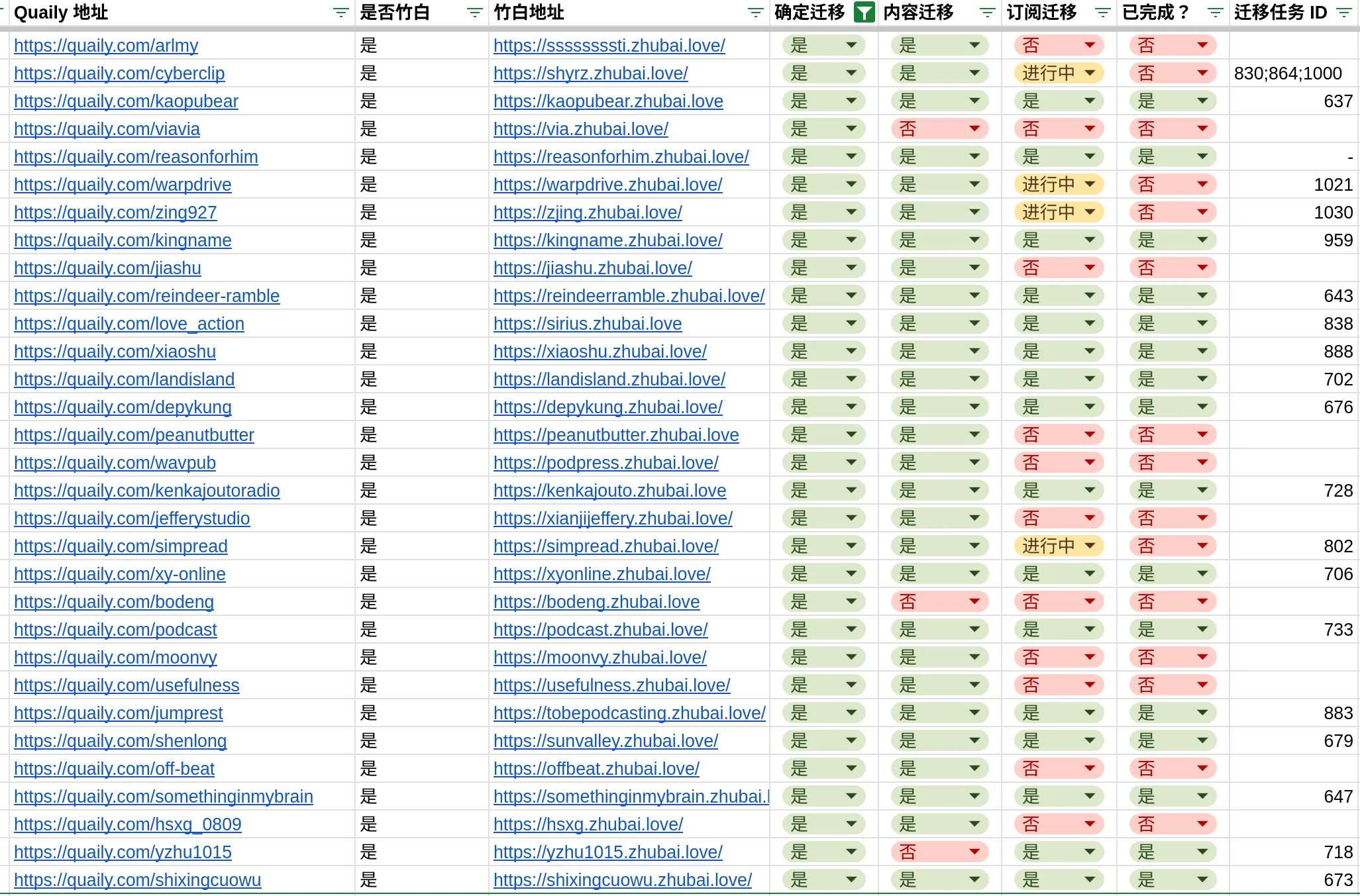
最后,我自己维护了一个 Google Sheets 来记录迁移的进展
一些优化
预迁移
一些作者在竹白上发了迁移公告,还没有邮件联系我,我已经把内容给迁移完毕了。
于是当他们给 Quaily 发邮件时,我会回复内容已经迁移完了,他们会很开心。
这是因为对于新创建的 Quaily 频道,我会得到通知。然后我会去看看竹白上有没有同名的。如果有的话,并且作者声明授权的迁移目的地也对得上,就可以直接迁移了。
这样的体验比较好。
Onboarding
观察了一些作者的使用习惯以后我发现:
- 竹白似乎不支持完整的 Markdown,所以写了「五分钟掌握 Markdown」来帮助作者们学习 Markdown
- 不少作者同时经营公众号,那么把微信公众号排版功能介绍给作者
最后挑选了一些中文作者可能感兴趣的话题,在文章「✉️ 给中文创作者朋友的信」一起集中介绍,并在迁移邮件中推荐作者阅读和订阅。
感谢竹白
Quaily 刚刚起步时,就收到了不少竹白作者的信任——像 一石千浪,DEX 周刊 和 AIGC Weekly,都是最初就选择了 Quaily 的几位。也正因为大家的鼓励,我才有了更多前进的动机。
没想到到了最后,Quaily 的导入在竹白下线时也帮到了更多作者。
感谢竹白和竹白的创作者,有了大家,Quaily 才像今天这样具备一定的承载力,也让我有机会遇见你们。
以上。